Hadoop数据处理基本过程回顾
Hadoop是一个分布式的、高度容错的数据存储和数据处理架构,主要包括两个部分:HDFS文件系统:一个分布式的、容错的、自愈的、自平衡的海量集群文件系统。
MapReduce计算框架:一个分布式的、容错的、大规模并行数据处理模型和资源管理调度系统。
MapReduce计算的处理过程如下:
.jpg)
先将文件按大致固定的大小及分隔符特征,将一个文件分割为多个Split,MapReduce作业调度算法会安排该Split文件分片所在的节点启动一个Map task,该task会对该文件分片进行Map操作。
每个Map任务有块内存(io.sort.mb)存放map函数的输出。
Map的中间结果会先存储在节点上的内存循环缓存In-Memory Buffer中,当缓存快溢出时,将Map中间结果吐出到节点本地文件系统中的一个临时文件,此时的临时文件的内容是按Key分区Partition的并按Key排序的(Key:Value),Map task会继续处理Split文件分片,吐出相应的Map临时文件,直到Split文件分片处理完毕。
Shuffle就是Mapper的输出传给Reducer的过程。
Shuffle Map端:Map task在将所有Split文件分片处理完毕后,会进入Map端Shuffle过程,会将内存中的以及所有的存储在本地文件系统中的Map中间临时文件按各个Partition应当输出到的Reduce task合并排序,即将所有需要输出到相同Reduce task的Partition合并在一起,合并成一个已分区且排序的文件作为map的输出。
Shuffle Reduce端:Reduce任务会在所有的Map任务完成前就启动,进入复制阶段(copy phase),获取heartbeat中传过来的已经完成的Map任务列表,从map任务那里通过HTTP并行的取得属于这个reducer的map输出,合并不同map输出成一个有序的文件,当所有的map输出都被合并成一个有序文件后,reduce函数启动。
Reduce task会将处理结过输出到HDFS文件系统的文件中。
以上描述了MapReduce的处理过程,小编在此只想通过以上描述得出以下结论:
HDFS文件系统是按固定大小的数据块(通常为64MB、128MB等,Oracle的BDA采用256MB的块大小)均匀分布在所有存储节点的所有硬盘上(理想情况下)。
MapReduce会尽量用文件分片所在节点来处理该文件内容,即Hadoop具有数据处理本地化特征。
HDFS文件系统不具有文件系统缓存层,即HDFS不会如通常的文件系统那样,通过LRU算法实现常用数据块的缓存,当然也不会安排数据预读进缓存备用。对于写,也是如此,HDFS会等待数据块写的三个副本都已完成,数据块写才算完成。
HDFS的数据块最底层是写在每个数据节点上的本地文件系统上的,如EXT4、Btrfs等,这些本地文件系统还是具有文件系统缓存的,这是HDFS底层支持系统所具有的,而不是HDFS文件系统层所具有的。
Hadoop架构的经典部署方式
Hadoop的经典部署方式,就是采用采用计算与存储紧耦合方式,如下图:

Hadoop经典部署方式采用统一的节点配置,该节点上将安装和运行HDFS文件系统及MapReduce计算框架。
经典部署方式是最早的Hadoop架构部署方式,可以完全支持和充分发挥Hadoop固有的数据访问和处理的本地化特征。
经典部署方是也是目前最广泛采用的部署方式,但随着人们在大数据领域用经典部署方式来架构和处理大数据,经典部署方式的不足之处也开始逐步显现,主要表现在:
Ø 经典部署方式由于采用统一的节点配置,其计算能力与存储能力在部署之初就形成了一个固定配比,虽然整个Hadoop集群可以随着节点的增加扩展其计算处理和数据存储能力,但由于固定配比的存在,其计算处理能力和数据存储能力并不能独立扩展,影响了整个架构的灵活性。
Ø 经典部署方式由于采用统一的节点配置,无法快速采用一些新的服务器技术,如目前出现的高存储容量的存储服务器、GPU优化的计算服务器、FPGA优化的计算服务器、内存优化的服务器以及低成本高密度计算服务器。
Ø 经典部署方式与HDFS文件系统紧耦合,HDFS面向大文件的设计特点使得HDFS文集系统不善存储巨量的小文件,在巨量小文件面前,NameNode的瓶颈就容易出现,限制了HDFS文件系统的扩展性。
Ø 经典部署方式由于将所有数据都存储于HDFS文件系统,HDFS的访问通常限于Hadoop生态系统,即通过MapReduce或更高级的Pig、Hive等方式访问,其他生态系统的框架必须有相应的连接器才能访问。据此,有观点认为HDFS并不是做为企业级数据湖的最好选择。
目前通常将Hadoop的经典部署方式简称为Hadoop 1.0。
Hadoop架构的融合部署方式
Hadoop的融合部署方式是将Hadoop的HDFS文件系统与MapReduce计算框架分开部署的一种部署方式,如下图:
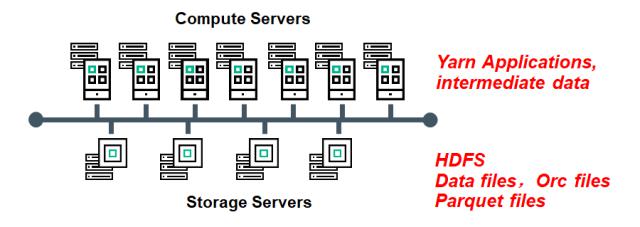
通常采用存储优化的超大容量存储服务器构建HDFS集群,采用计算优化的计算服务器(如高密度的计算服务器、GPU优化的计算服务器、FPGA优化的计算服务器等)组成Map Reduce计算集群。计算集群与存储集群之间通常采用专用的网络连接。
融合部署方式使得计算节点与存储节点没有固定配比,该部署方式使用户可以在计算资源和存储资源各自独立扩展。
融合部署方式使得用户可以根据需要灵活选择计算服务器和存储服务器型号,充分利用存储服务器的存储容量和计算服务器的计算特性,从而构建一个更加灵活和适应新技术的Hadoop部署架构。
融合部署方式虽然带来了更加灵活的扩展特性,但融合架构也带来了其他的不足:
Ø 融合部署方式破坏了Hadoop固有的数据访问本地化特性。所有的数据访问必须经过数据网络。随着网络向25G和100G的普及,该不足在逐渐淡化。
Ø 融合部署方式仍然与HDFS文件系统紧耦合,HDFS面向大文件的设计特点使得HDFS文集系统不善存储巨量的小文件,在巨量小文件面前,NameNode的瓶颈就容易出现,限制了HDFS文件系统的扩展性。
融合部署方式由于将所有数据都存储于HDFS文件系统,HDFS的访问通常限于Hadoop生态系统,即通过MapReduce或更高级的Pig、Hive等方式访问,其他生态系统的框架必须有相应的连接器才能访问。据此,有观点认为HDFS并不是做为企业级数据湖的最好选择。
Hadoop架构的缓存优化虚拟分布式存储部署方式
Hadoop的缓存优化虚拟分布式存储部署方式是将MapReduce计算集群与存储系统分开部署,将计算资源与存储资源解耦,MapReduce集群与存储系统通过网络相连。
在MapReduce计算集群的所有节点上构建一个统一的分布式内存缓存资源池,在该资源池的前端,提供HDFS兼容的访问接口;在该资源池的后端提供整合Oracle Storage Cloud对象存储的后端接口,并可以将Oracle MapReduce各计算节点内置的PCI-E NVME统一做为二级缓存,将SSD或HDD统一做为三级缓存,以扩大分布式内存缓存资源池的容量。智能缓存调度算法在各缓存层级间智能缓存和预读最可能用到的数据。各计算节点各自并发地访问存储在Oracle Storage Cloud的对象数据。
缓存优化虚拟分布式存储通过智能缓存算法,理想情况下将大部分数据访问由内存缓存和本地SSD/HDD缓存实现,只有少数数据访问通过访问外部的对象存储实现。
Oracle帮助过客户通过智能缓存系统达到十几倍的性能提升。
该部署方式具有如下优点:
Ø 计算节点与存储容量没有固定配比,该部署方式使用户可以在计算资源和存储资源各自独立扩展。
Ø 用户可以根据需要灵活选择计算服务器型号和Oracle Storage Cloud的服务级别,充分利用对象存储的海量容量和多种服务级别。
Ø 对象存储的供给远比HDFS快,且自愈速度也比HDFS快。
Ø Oracle Storage Cloud会将每个对象在Region的三个可用域各存一个副本,远比HDFS的跨机柜副本放置策略的可靠性高。
Ø Oracle Storage Cloud可以很简单地实现跨Region的复制,而HDFS要实现跨区域的数据复制将非常困难。
Ø 由于采用了统一的内存缓存池,加上各节点上的NVME、SSD和HDD组成的大容量的二级和三级缓存,加上智能的缓存调度算法和预读策略,通常会带来较大的性能提升。
Ø 对象存储由于访问的通用性,可适应各种计算框架,更适合作为企业的数据湖存储。
缓存优化的虚拟分布式存储部署方式有时也简称Hadoop 2.0。
Hadoop环境下处理大量小文件的问题
前文提到了HDFS在处理大量小文件时候会遇到瓶颈。主要是因为HDFS通常有一个Master的NameNode和一个Standby NameNode,当然,从技术上讲,用户可以配置多个Standby NameNode,但Master NameNode默认只有一个,搭建NameNode HA步骤很繁琐(Oracle Bigdata Cloud Service提供2个Master节点的高可用保障)。Master NameNode会将HDFS文件系统的MetaData保存在内存中(MetaData被持久化到磁盘文件fsimage中,NameNode启动时会先读取这个信息),任何对Master NameNode的MetaData更改会在修改内存的同时,将修改添加到本地磁盘log文件edits中,其余Standby NameNode会实时获取该Log,并将变化同步到Standby NameNode的内存中。
在HDFS文件系统中,任何一个文件、目录和Block都会被表示为一个Item存储在 NameNode的内存中,每一个Item占用150~200bytes的内存空间。所以,如果有一亿个文件,每一个文件对应一个Block,那么就会消耗NameNode 30~40G来保存这些MetaData的信息。如果规模再大一点,如10billion的文件,就需要3TB~4TB的内存,那么将会超出现阶段计算机硬件所能满足的极限。
目前关于避免NameNode瓶颈的技术思路主要是分布式MetaData管理和Key/Value管理Namespace。
分布式MetaData的基本思想是将文件系统的命名空间root及全部命名空间先由分布式MetaData集群中的一个节点管理,随着文件系统负荷增加,将命名空间树形结构中的最忙碌的分支迁移到另一个节点管理,依次循环往复,动态保持整个命名空间在MetaData集群节点间的访问负荷平衡。
Oracle在Big data Cloud Service-Compute Edition中实现了一个统一的命名空间(Big data file system,BDFS),该命名空间可以将其一个或多个目录映射到Oracle Storage Service对象存储的一个或多个container,利用计算节点的内存、NVMe和HDD做为统一的缓存。Big data file system仅需管理缓存在计算节点的数据块的MetaData,无需管理整个命名空间的MetaData,整个命名空间的MetaData由底层的存储系统Oracle对象存储管理。
对象存储通常采用Key/Value方式管理MetaData。用户在统一命名空间中的一个文件会自动映射到对象存储中的一个对象,对象存储计算对象名的Hash值,通过Hash值得到该对象的对应的Placement Group ID, 再利用该Placement Group ID、当前各节点的状态图和事先定义的规则计算出负责该Placement Group的对象存储节点,在该存储节点就可以得到该对象的内容。
通过以上描述,我们可以知道,Oracle Big data file system自身并不需要管理整个命名空间的MetaData,通过映射文件到对象,对象存储仅需进行简单的计算就可以直接找到我们文件所需要的文件。
所以,Oracle Big Data file system虚拟分布式文件系统能快速处理小文件,且没有MetaData性能瓶颈。
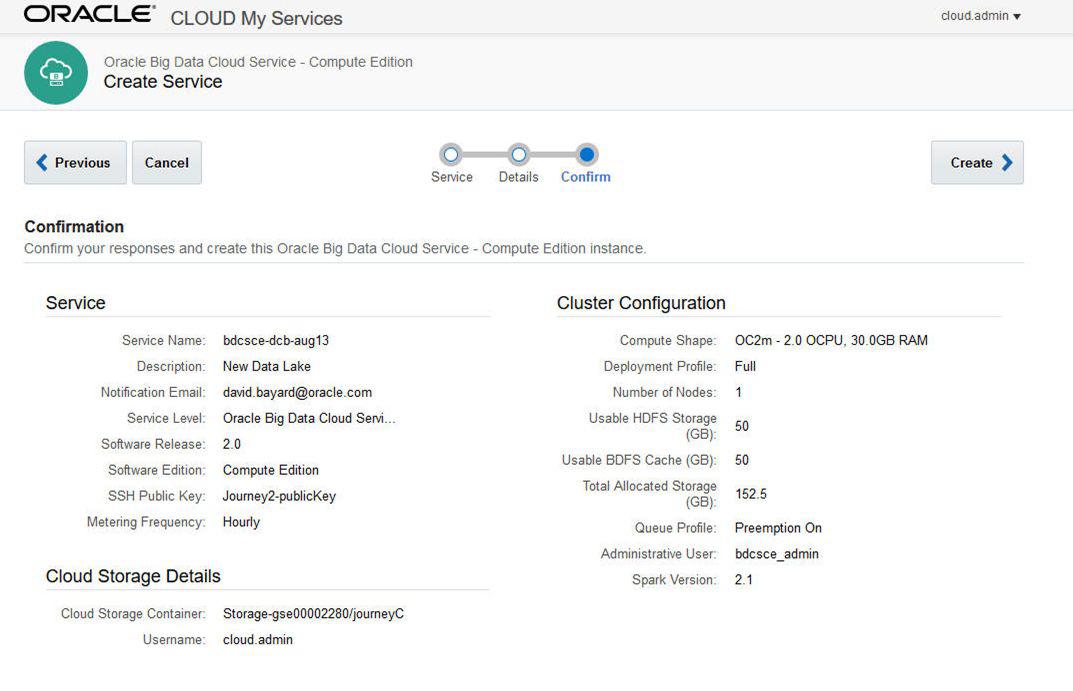
仅需三步,就可以在Oracle公有云上部署Big data Cloud Service, 以上是一个服务的订阅情况:一个节点(2个OCPU, 30GB内存),分配了50GB给HDFS,分配了50GB给Oracle BDFS文件系统做缓存,BDFS文件系统映射到了一个后端的对象存储的Container。
总结
Hadoop的几种部署方式客官可以根据自己的情况选择,Hadoop 1.0温柔贤惠,Hadoop 2.0前卫时尚。
Oracle是业界公认的数据管理和大数据分析领域的领导者,我们不仅有业界领先的关系型数据库,我们还有基于Hadoop的大数据平台,并能将关系型数据库与Hadoop平台很好地集成在一起,提供全数据解决方案和云服务。
Oracle还将Machine Learning机器学习算法集成在关系型数据库和分析平台中,帮助用户在各种数据中发现价值。
对于Hadoop的部署,Oracle全面支持Hadoop 1.0和2.0部署方式,客官可以选择BDA大数据一体机/OCC公有云一体机/BDCC公有云大数据一体机及BDCS大数据云服务,客官还可选择在自己数据中心和Oracle公有云部署自己的Hadoop。
各部署方式的特点及Oracle对应的产品和云服务见下表:
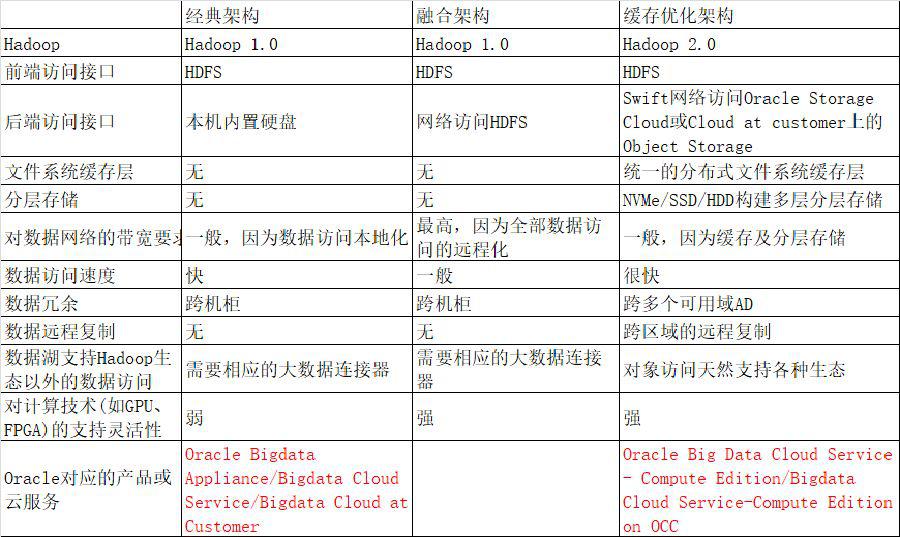
Oracle Big Data Cloud Service-Compute Edition提供了基于缓存优化的虚拟分布式存储部署方式,充分利用了内存及本地SSD/HDD的高性能和对象存储的高可靠性和高性价比,同时又能很好地处理小文件。
【文章来源:Oracle官网】